TL;DR: An OpenClaw fallback model is the secondary model in the agents.defaults.model.fallbacks array that takes over when the primary hits a 429, billing block, or auth failure. Add one with openclaw models fallbacks add <model> or by editing the fallbacks list in ~/.openclaw/openclaw.json. Order matters: the first reachable model in the list wins, top to bottom.
The fallback chain has two stages OpenClaw runs in order. Stage one is auth-profile rotation INSIDE a provider. If your first Anthropic key is rate-limited, OpenClaw tries the next set Anthropic key for the same model before the model is marked down.
Stage two is model fallback ACROSS providers. Once every auth profile for the primary is in cooldown, OpenClaw walks the fallbacks array top to bottom and picks the first model that isn't itself in cooldown.
The cooldown schedule doubles each time: 1 minute on the first failure, then 5, 25, and 1 hour. Every 5 minutes after a fallback takes over, OpenClaw quietly retries the primary in the background and switches back when it succeeds. A separate billing-disabled backoff starts at 5 hours and doubles to a 24-hour cap.
Four bugs make this less reliable than the spec implies:
- Issue #47705 persists the fallback to openclaw.json, replacing the primary for good.
- Issues #5763 and #22136 skip the fallbacks entirely when the primary is in cooldown rather than rate-limited.
- Issue #20265 makes
fallbacks addsilently create an allowlist that excludes the primary. - Issue #59928 leaves sessions stuck on the fallback after the primary recovers.
The openclaw fallback config below sidesteps all four.
How to add an OpenClaw fallback model (the working config)
The openclaw fallback configuration lives in agents.defaults.model.fallbacks in ~/.openclaw/openclaw.json. The shortest path to add to it is openclaw models fallbacks add <provider>/<model> from the CLI: it writes the new entry to the file, the gateway picks it up on the 300ms reload debounce, and the next openclaw models list shows the new fallback in the chain.
Order in the array matters and the CLI appends, so if you want your new model first you'll still need to open the config and reorder.
My working config has Sonnet primary, DeepSeek as the cheap escalator, and Gemini Flash-Lite as the bottom of the stack. Three providers, three different rate-limit clocks, and a fair chance one of them is awake when the others aren't. Here is the block I paste:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4.5",
"fallbacks": [
"deepseek/deepseek-v3.2",
"google/gemini-2.5-flash-lite"
]
},
"models": [
"anthropic/claude-sonnet-4.5",
"deepseek/deepseek-v3.2",
"google/gemini-2.5-flash-lite"
]
}
}
}Note the models array under agents.defaults: if it's defined, every entry in fallbacks plus the primary has to also be listed there, and the CLI add-command doesn't always include the primary (bug #20265 below).
Method 1: CLI (the safe one)
Three commands cover the full flow:
- Run the add-command for your target:
fallbacks add deepseek/deepseek-v3.2. - Verify with
openclaw models listto see the new entry under thefallbackstag. - Confirm the model name parsed correctly by checking the chain in
~/.openclaw/openclaw.json.
The command runs in about a second, writes to disk, and the gateway hot-reloads. I call this the safe path because the CLI handles JSON5-to-JSON normalization for you.
Method 2: direct openclaw.json edit (and why I prefer this)
Vim, nano, whatever. Open ~/.openclaw/openclaw.json, find agents.defaults.model.fallbacks, add your entry, save. The 300ms debounce means the gateway reloads on its own.
Port 18789 stays up, no restart unless something else is wrong (see H2 6). The hot-reload is debounced for that reason: operators tend to make many edits in a row when wiring a chain.
I got bitten by #20265 twice in one week before I dropped the CLI for this operation.
Before you can configure a fallback you need at least two models registered: that part is the same regardless of which method you use here.
What an OpenClaw fallback model actually is (the two-stage failover)
Now you have a config. Here's the mental model that lets you debug it when something goes sideways. OpenClaw's failover runs in two stages, and most tutorials I've read conflate them. The conflation is why people assume fallbacks will catch every kind of failure. It won't.
Stage one is auth-profile rotation INSIDE a single provider. If you've set up many Anthropic API keys (or an Anthropic OAuth login plus a backup API key, which is the Codex-subscription-plus-backup pattern), OpenClaw rotates through them on quota or auth errors before it marks "Anthropic" itself down.
Stage two is model fallback ACROSS providers. Once every auth profile for the primary model has failed or entered cooldown, OpenClaw walks the fallbacks array. The model changes; usually the provider changes too. This is what most people mean when they say "fallback," and the array order is what dictates which model gets tried.
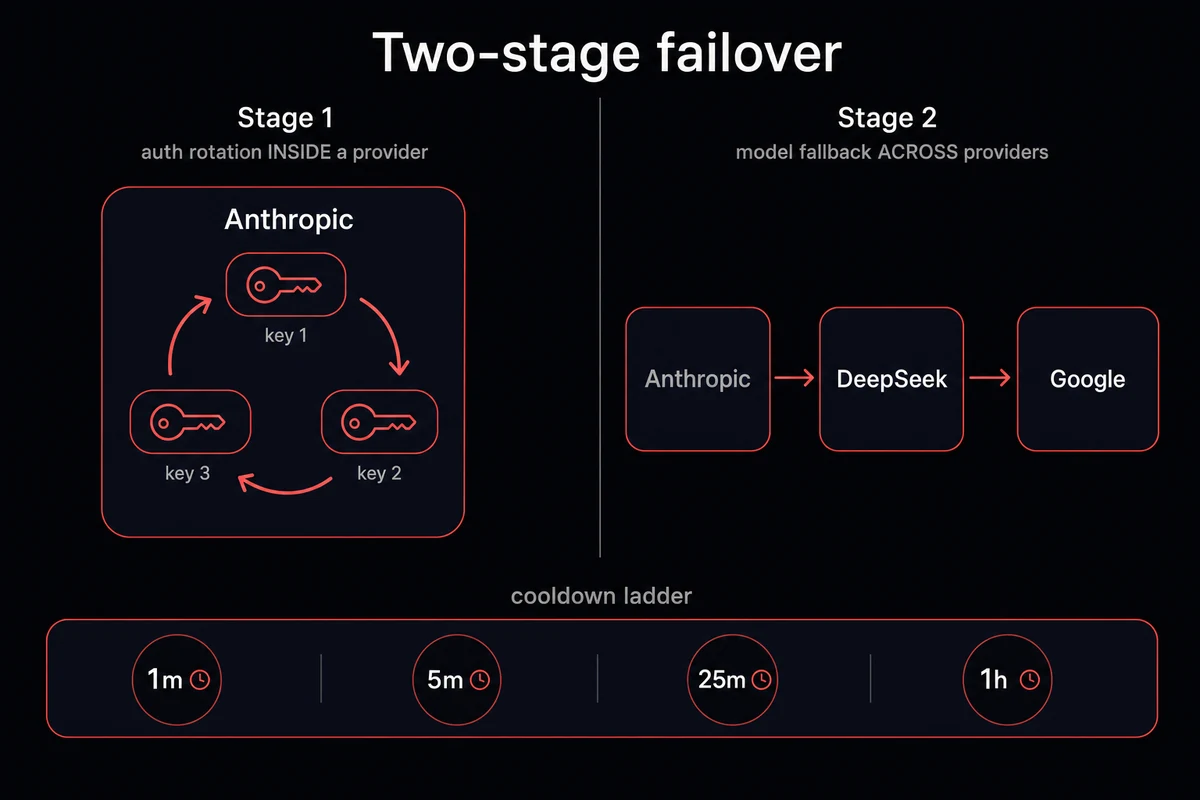
The openclaw cooldown rate limit ladder doubles each step. First 429: 1-minute cooldown. Second consecutive: 5 minutes. Third: 25 minutes. Fourth and beyond: 1 hour, repeating until the model serves a successful response.
The retry-after cap inside the SDK is 60 seconds. If the provider sends a Retry-After header asking for longer, OpenClaw stops waiting at 60 and falls through to the next model in the array. That's the line between "wait it out" and "give up and fall back."
Billing-disabled errors take a separate path: backoff starts at 5 hours, doubles per failure, caps at 24 hours. The fallback array still gets walked while the billing-disabled provider sits out.
The primary-probe interval is 5 minutes. After a fallback takes over, OpenClaw quietly hits the primary in the background every five minutes. The moment the primary responds, the next new session lands back on it. Existing sessions are where issue #59928 bites; we get to that in H2 6.
Choosing the right fallback model (cost, quality, reachability)
Three framings work for picking a fallback. Fallback as backup pairs an expensive primary with a cheap safety net; fallback as escalator inverts that with a cheap primary and frontier fallback for hard tasks; fallback as cost-tier sets a different chain per agent. I mix all three, and the H3 below covers the cheaper-than-primary default.
| Model | Per 1M tokens | Tier | Instruction following |
|---|---|---|---|
| Xiaomi MiMo-V2-Flash | $0.40 | cheap | not measured |
| Gemini 2.5 Flash-Lite | $0.50 | cheap | not measured |
| DeepSeek V3.2 | $0.53 | cheap | not measured |
| GLM 4.7 | $0.96 | cheap | not measured |
| GPT-5 | $11.25 | frontier | not measured |
| Gemini 3 Pro | $14.00 | frontier | not measured |
| Claude Sonnet 4.5 | $18.00 | frontier | 9/12 runs held SOUL.md |
One number worth carrying into the picking decision: per-model OpenClaw testing showed Sonnet 3.5 holding SOUL.md instructions 9 of 12 runs vs GPT-4o drifting in 3 of 12. The difference shows up in whether your fallback ships a usable answer or a confidently-wrong one during the 90 seconds the primary is rate-limited.
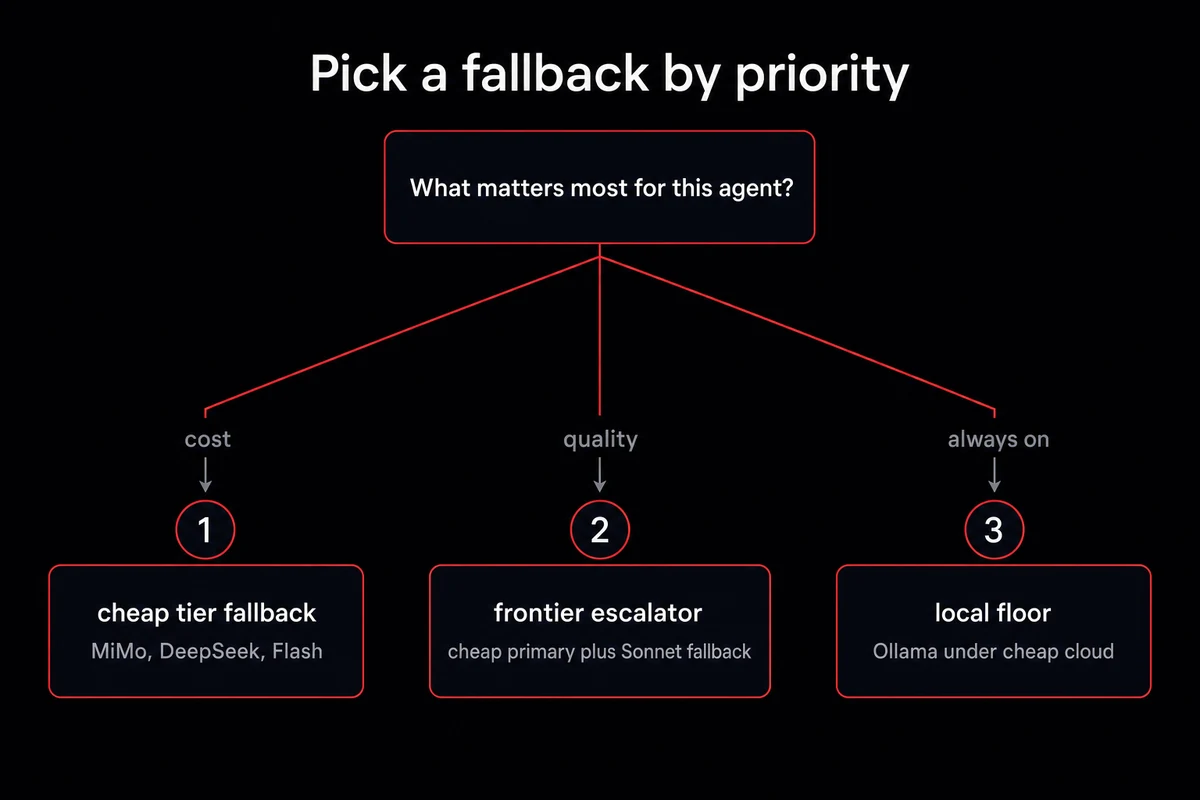
When the fallback should be cheaper than the primary
This is the default and it's right most of the time. Sonnet primary, DeepSeek V3.2 fallback at $0.53/M. The cost differential ($18.00 vs $0.53 per million tokens) is so large that you basically pay nothing during the primary's outage windows.
The tradeoff is quality during those windows (DeepSeek is not Sonnet), but cheap fallbacks bridge 90-second cooldowns fine. They struggle when you need them to do four hours of work because the primary is billing-blocked. Plan for that in your monitoring.
DeepSeek V3.2 at $0.53/M shows up in roughly half the r/openclawsetup configs I've read this quarter, more than any other cheap-tier candidate. If you want the full DeepSeek setup walkthrough, that's the wiring side covered separately.
Gemini 2.5 Flash-Lite at $0.50/M is the other shortlist entry. Xiaomi MiMo-V2-Flash at $0.40/M is the cheapest workable option, though a small handful of operators reported it dropping requests under sustained load.
When the fallback should be stronger than the primary
The escalator pattern. Run Haiku or a local Gemma model as primary, set Sonnet 4.5 as the fallback. Every agent that completes its job on the cheap model never costs you frontier dollars.
Every agent that hits a wall (refusal, low-quality output, tool-call failure) falls through to the strong model. Volume agents like heartbeats and cron checks run for pennies. Operators on r/openclaw report per-request token costs dropping from 20-40k to 1.5k just by routing smarter.
Free tiers don't rescue real outages: OpenRouter free caps at 20 requests per minute and Gemini 2.5 Flash free at 1,500 per day. Production load burns through the limit inside an hour.
Hand-wiring multi-provider fallback chains gets tedious after the third or fourth chain: pricing decisions, API keys, allowlist gotchas, watchdogs, the JSON5-to-JSON config drift. OpenclawVPS provisions a dedicated VPS running OpenClaw with sensible model defaults already wired in. BYO-API-key supported across providers. Plans start at $19/month.
Per-agent fallback chains (when one fallback isn't enough)
A global agents.defaults.model.fallbacks covers every agent that doesn't override. Set per-agent chains under agents.<name>.model.fallbacks and the per-agent block wins. A 5-tier r/openclawsetup config looked like: heartbeat on gemma3:4b with GLM-4.5-Air as fallback; standard on gemma3:27b with MiniMax-M2.7 as fallback; coding on gpt-5.3-codex with devstral-small-2:24b as local fallback.
The JSON shape is the same as the global block, just nested one level deeper:
{
"agents": {
"heartbeat": {
"model": {
"primary": "ollama/gemma3:4b",
"fallbacks": ["zhipu/glm-4.5-air"]
}
},
"coding": {
"model": {
"primary": "github-copilot/gpt-5.3-codex",
"fallbacks": ["ollama/devstral-small-2:24b"]
}
}
}
}If you just need to switch the primary mid-session, that's the /model chat command: a different operation at a different layer, a one-letter typo away from changing meaning if you confuse it with persistent fallback config. The agent-level config itself lives in the same file where you registered each agent.
Local-model fallback (Ollama, LM Studio, vLLM)
Local fallback is the bottom of the stack: the floor that catches everything when every cloud provider is having a bad day. OpenClaw's default detection endpoints are http://127.0.0.1:11434 for Ollama, http://localhost:1234/v1 for LM Studio, and http://127.0.0.1:8000/v1 for vLLM. Wiring Ollama to OpenClaw takes the same five values whether it's primary or fallback.
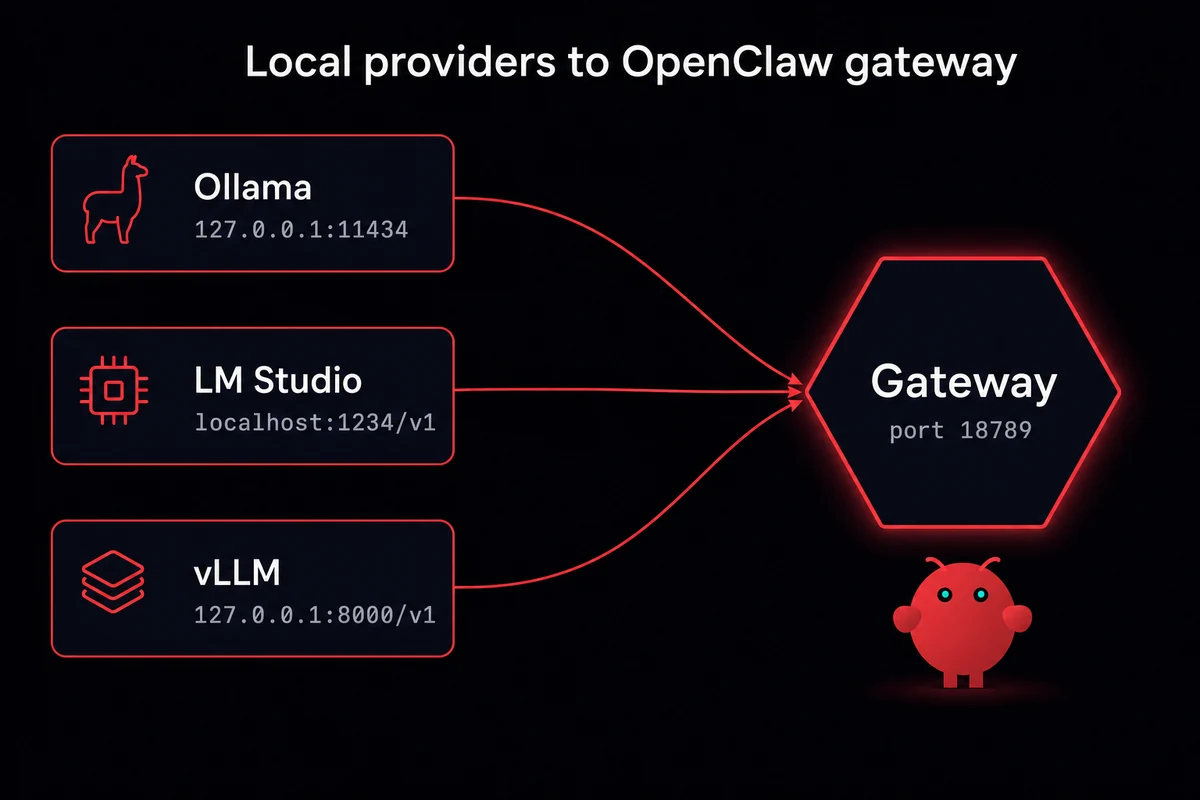
Local fallback is not free fallback. You pay in latency on consumer hardware and in quality (a 7B local model is not a frontier model), but you don't pay per million tokens and you don't get rate-limited by a third party.
The order I run is cheap-cloud first, local-fallback last. Reverse the order and the local model gets used during every cloud cooldown, slowing every agent to a crawl on routine 429s.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4.5",
"fallbacks": [
"deepseek/deepseek-v3.2",
"ollama/devstral-small-2:24b"
]
}
}
}
}Load the model first with ollama pull devstral-small-2:24b. The first request after a cold start takes 20-40 seconds while Ollama loads weights; keep the model warm with a periodic heartbeat or accept that the first failover request will be slow.
Why your OpenClaw fallback isn't triggering (four bugs, four workarounds)
Four bugs are open against the fallback subsystem as of mid-2026, and I've hit three on real workloads. The table below is the scannable reference; sections beneath walk each one with the workaround.
| Bug | Issue # | Symptom | Affected version | Workaround |
|---|---|---|---|---|
| Sticky-fallback | #47705 | Fallback persists to openclaw.json, replacing primary | 2026.3.13 | Back up openclaw.json before fallback-prone sessions; manual config restore |
| Cooldown-skip | #5763 / #22136 | Fallbacks not attempted when primary is in cooldown | 2026.1.30 / 2026.2.19-2 | Shorten cooldown ladder; watchdog forces manual switch |
| Allowlist trap | #20265 | models fallbacks add excludes primary from allowlist | 2026.2.14 / 2026.2.17 | Add primary explicitly to allowlist or use JSON edit method |
| Primary-not-resurrected | #59928 | Sessions stuck on fallback after primary recovers | 2026.4.2 | Restart gateway after known primary outage |
Bug 1: Sticky-fallback (#47705, 2026.3.13). When a session switches to a fallback, the internal applyAgentConfig() writes the current model back to agents.<name>.model.primary, deleting the original primary from disk. Daily config backup is on the day-1 checklist on any 2026.3.x build; the reporter saw 6+ occurrences over 5 days.
Bug 2: Cooldown-skip (#5763, 2026.1.30; #22136, 2026.2.19-2). The canonical openclaw fallback not triggering mode: primary enters cooldown, zero configured fallbacks get attempted. The #22136 reporter logged ~4.5 hours of service failure with three fallbacks listed. I run a watchdog against my own gateway that calls openclaw models set-primary after three primary failures in a row, cutting my median outage to about three minutes.
Bug 3: Allowlist trap (#20265, 2026.2.14 / 2026.2.17). Running openclaw models fallbacks add against agents.defaults.models = "all" silently overwrites models to a single-entry array, leaving the primary disallowed and returning "model not allowed" on the next run. Fix it by adding the primary to the models allowlist or editing the JSON directly.
Bug 4: Primary-not-resurrected (#59928, 2026.4.2). Sessions started during the fallback window stay routed to the fallback even after the 5-minute primary-probe succeeds. The reporter saw openai-codex/gpt-5.4 recover at the provider while existing sessions kept on the configured fallback. Restart the gateway after any known outage so new sessions resolve to the recovered primary; existing sessions need a hand-switch.
Quick triage flowchart (5 questions to figure out which bug you hit)
When the fallback misbehaves, walk these in order:
- Did your openclaw.json file change on its own, with the primary entry swapped out? If yes, you hit #47705.
- Is the primary in cooldown according to
openclaw models listbut no fallback got attempted? That's #5763 / #22136. - Are you getting "model not allowed" errors right after using the add-command? That's #20265.
- Did the primary recover but your sessions are still on the fallback? That's #59928. Restart the gateway.
- None of the above? Check whether your fallback model is itself in cooldown.
openclaw models listshows the status.
Cooldown on a fallback is the easiest miss. The chain just walks past it to the next entry, and if there is no next entry the agent fails outright.
Four documented bugs, three months of operator-time burned across them, and you're still managing the watchdog yourself. OpenclawVPS ships a managed OpenClaw runtime with the working-config defaults already in place and BYO-API-key across the providers covered above. EU regions in Falkenstein, Nuremberg, and Helsinki. Provisioning takes 47 seconds.
The setup I run now
The hand-wired three-provider chain works, but the watchdog scripts, openclaw.json backups, and JSON5 normalization gotchas are real overhead. OpenclawVPS provisions a dedicated VPS running OpenClaw with sensible model defaults wired in, BYO-API-key across providers, and EU regions. Provisioning takes 47 seconds.